KMP(Knuth-Morris-Pratt)算法
KMP(Knuth-Morris-Pratt)算法是一种用于字符串匹配的高效算法,由 Knuth、Pratt 和 Morris 在 1977 年共同发布。该算法通过预处理模式串来减少匹配过程中的回溯次数,从而在最坏情况下实现线性时间复杂度。KMP算法也是前缀函数的一个应用,我们首先了解一下前缀函数。
前缀函数
前缀函数(Prefix Function)是KMP算法中的核心部分,用于在模式串匹配失败时,确定下一步匹配的位置。前缀函数对于字符串的每个位置,记录了该位置之前的子串中,有多大长度的前缀同时也是后缀。
定义
对于一个字符串P,其前缀函数pi[i]表示P中以位置i结束的子串P[0...i]的最长前缀,这个前缀同时也是这个子串的后缀(不包括整个子串本身)。
例如,对于字符串P = "ababaca",其前缀函数数组pi如下:
pi[0] = 0(单个字符没有前后缀)pi[1] = 0(”ab”的前后缀没有相同的)pi[2] = 1(”aba”的最长前后缀是”a”)pi[3] = 2(”abab”的最长前后缀是”ab”)pi[4] = 3(”ababa”的最长前后缀是”aba”)pi[5] = 0(”ababac”的前后缀没有相同的)pi[6] = 1(”ababaca”的最长前后缀是”a”)
因此,前缀函数数组pi为:[0, 0, 1, 2, 3, 0, 1]
代码实现
1 | vector<int> prefix_function(string s) { |
KMP算法概述
以一道经典题目为例:
力扣题目链接 (opens new window)
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1: 输入: haystack = “hello”, needle = “ll” 输出: 2
示例 2: 输入: haystack = “aaaaa”, needle = “bba” 输出: -1
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
所以如何记录已经匹配的文本内容,是KMP的重点,这就是为什么我们需要前面说的前缀函数。通常我们把这个前缀函数也称为next数组
我们举个例子来看KMP是怎么操作的,假设主串S=“aabaabaaf”,子串T=“aabaaf”,我们已经求出了子串T的前缀表,采用KMP算法匹配的流程如下:
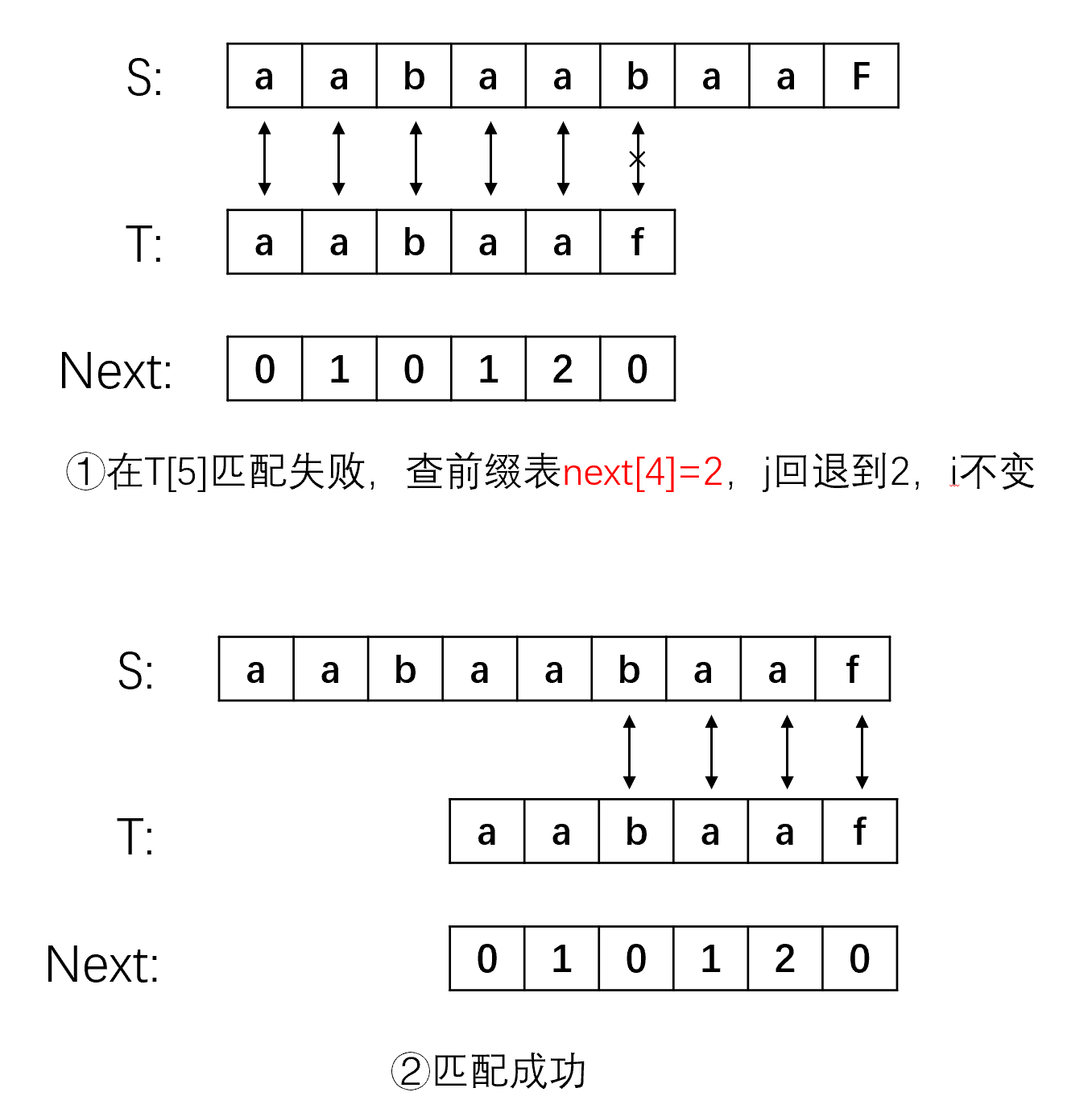
从上面的流程可以看到,用两个指针来匹配,i、j分别从S、T首位开始匹配,在子串的某一个字符t[j]处匹配失败时,我们需要查找该字符前面的那个子串的最大相等前后缀的长度,即next[j-1],然后使j指针退回到next[j-1],i指针不变,继续匹配,不断重复这个操作知道匹配成功或者j指针大于等于子串长度。在这里j指针之所以退回到next[j-1]的位置,是字符”f”前面的子串为”aabaa”,该子串的最大相等前后缀为”aa”,而该子串的后缀”aa”已经与s[3]s[4]比较过是相等的,那么子串的前缀就一定是与s[3]s[4]相等的,不需要比较,因此我们的j可以从前缀的后面第一个字符开始匹配,而前缀的长度为next[j-1],所以j应该回退到next[j-1]。
代码实现
1 | class Solution { |